I recently wrote a post that delved into why iterating and improving data products can take considerable time, what with all the work that goes into testing and rolling out the changes. Here I want to briefly flesh out some common simple scenarios as to why your data changes, and some guidelines for addressing them. Of course most products will be more complex than the simple example given, and multiple reasons for data changes will interact with one another.
Scenario: Step-counter
Let’s pretend you have developed a new step counter. We will also make some assumptions (and vast simplifications) about how it works.
- Accelerometers measure the initial steps
- This raw data is stored
- The raw data is converted into step count data
- Bonus: The raw and/or step count data is used to calculate other metrics (e.g. the number of calories burnt)
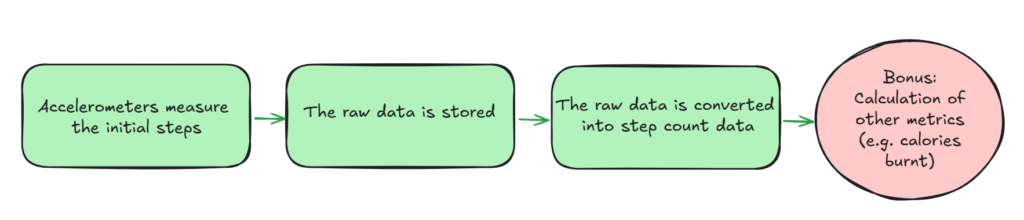
Very simplified data pipeline for a step counter.
Reason 1: Changing the input
Scenario: You update the way data is being fed into the system by having new accelerometers. Possibly you have updated to a new model, or have had broken ones replaced.
Consequence: Going forward actions you did before may produce a different result. For instance, your walk to the grocery store now may be counted as 2000 steps as opposed to 1900. This does not retroactively change your data, but the same input no longer creates the same output as before.
Note that there is not necessarily a straightforward way to reverse this change, short of switching back to the old model, or somehow virtually transforming the raw data to what would have been produced before.
Reason 2: Re-processing the raw data
Scenario: Due to a bug or spurious technical limitations, some part of the raw data was not correctly converted into steps. The processing of the raw data is re-triggered, and the processing happens correctly this time around.
Consequence: Historical changes to the data take place.
Note that in this case reprocessing the raw data may result both in changes in the step count, but then also on other metrics derived from it, such as the number of calories burned. If all the stored data gets reprocessed, then data can change for the whole duration the user had the device, and be impacted by many changes done since the product was purchased. Needless to say, the changes this could result in could be quite significant.
The interaction of the different factors with spurious errors means that reversing this change will be harder to reverse than for the first reason. I would argue that this is possibly the hardest to account for, of the three reasons listed here.
Reason 3: The calculation is updated
Scenario: You update the step count calculations on the transformed data.
Consequence: Data going forward changes. If the calorie count calculation relies on step count data, then this metric will also be affected. Not so if the calorie count is derived directly from the raw data. If the user were to then also reprocess their historic data (see Reason 2), then this will also change historic values.
Of the three reasons discussed here, this one is the easiest to reverse if necessary. The inputs after all remain the same, and you are changing only how you are manipulating them. If one were to so choose, you can go back to the previous way of calculating them.
Follow-up considerations: Controls, cascading effects and data meshes
One can see that each step of the data processing flow can be a cause of variation for your data, and thus the longer the processing chain, the more potential cascading effects you get. You can think of this as “raw data + n”. The higher the n, the higher the risk.
A contributing factor to the risk is how error prone your data processing is. Even the best pipelines will likely have some issues that will crop up, especially with larger volumes. The effect of these are harder to predict, and it is good to nip these in the bud. Hence one should invest in good monitoring capabilities throughout your data processing pipelines. You want to check that the data is being transformed as expected, and that you are not loosing any transactions along the way. You don’t want to have any data randomly mutating. Evolution may have yielded many incredible natural wonders, but it’s place is not in your product. And even cell replication has safeguards in place to detect errors, and minimising mutations.
While this will come up as no surprise to any data engineer, this is also important from a business perspective. It is an indication of the quality of the product you are building, and having safeguards in place will prevent having to deal with too many upset (and likely churning) customers down the line.
To state the obvious, changes in earlier stages in the processing pipeline are going to affect later steps, and these will also have effects that will be harder to predict or reverse. For a visually more pleasing example, see how fixing the Hubble telescope’s mirror (equivalent to changing the initial collection of the input in Reason 1) dramatically changes the output.

More visually striking images than what you are likely to get when upgrading the accelerometers in the step counter, but the principle is the same.
Another recommendation is to avoid having a single processing pipeline doing it all, and rather go for a data mesh approach. This in essence means each domain or team owning its own data pipelines, and provide the resulting data as a product for others to use. Among other benefits, one will have fewer intertwined calculations, which is good for controlling against unexpected changes. In our step counter example, the pipeline for calories burnt would be a separate flow from the step counting one, albeit one that may still use step count as an input for its calculation (represented below with a dotted arrow).
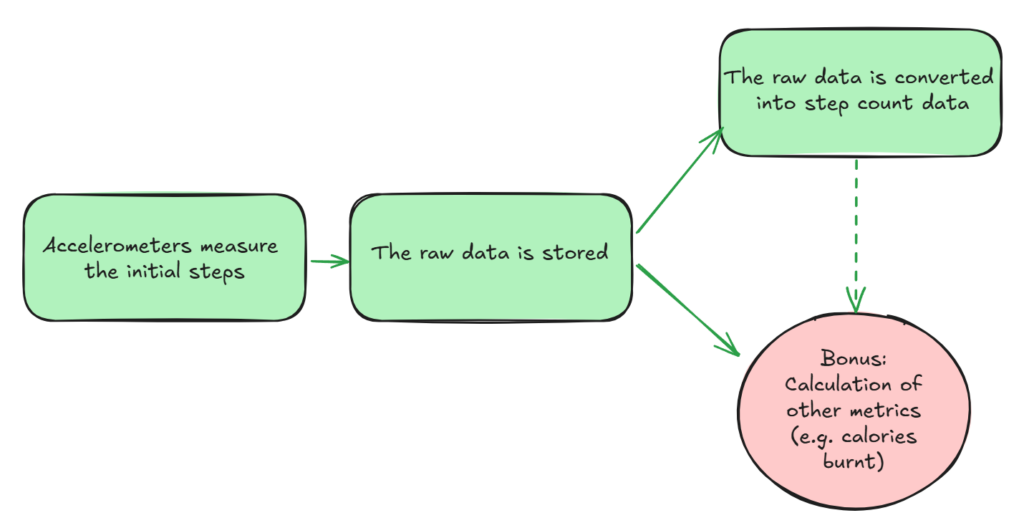
In a data mesh each significant metric is its own product, which can then be used be it as an output for the user, or as an input for other pipelines within the mesh. This helps counter unexpected changes, although there can be challenges in coordinating multiple pipelines.
Step count data may therefore still produce changes to the calculation of calories being burnt, but independent pipelines make these changes easier to test, reduces the likelihood of unforeseen changes having knock-on effects across metrics, and even allows easier versioning of data, so you could more easily maintain different data outputs.
Parting thoughts
People get upset when their data changes, and yet one can see that there are multiple drivers pushing for it to happen. If you have a successful product, you will also have the luxury of having to deal with shifting data. This post will hopefully have given you some first principles as to where these changes emerge from, and what mitigation strategies can be implemented.
Leave a Reply